

Release notes
VIANOPS v2.2 release notes
New features in VIANOPS v2.2:
-
Local explainability with what-if analysis
Local explainability shows how your machine learning models make individual predictions, helping you understand how a model makes decisions for a single instance. It helps answer why a model made a particular prediction; for example, why a specific person has been predicted to have a high risk of a disease. Local explainability can expose the root cause of a specific issues of a model in production. It answers which individual elements influenced a particular choice, making local explainability particularly critical for models used in regulated organizations.
What-if analysis helps you see what changes to outputs would result with given changes to inputs. You can play with feature values to find how they impact predictions, gaining valuable insights for optimizing model performance.
- See Explainablility.
-
You can upload training data and use it as the baseline window for drift analysis.
With training data as a baseline, you can create policies that compare metrics between the training dataset and production datasets. You can use training data to generate drift and performance metrics when creating or copying a policy.
- All policy types can use training data as baseline.
- See Upload training data.
-
Custom metrics
In addition to the standard performance and drift metrics, you can now create custom metrics to monitor performance that best fits your project needs. This enables all features, like performance, drift analysis, and model comparison to use metrics that are relevant to your use case.
You can define custom metrics based on the standard metrics that VIANOPS supports.
- Custom metrics appear in italics in all the UI elements where standard metrics appear.
- See Custom metrics.
Improvements and enhancements in VIANOPS v2.2:
-
You can select categorical features for hotspot analysis when creating a policy.
- In Hotspot by features section of the policy wizard, you can select which categorical features you want to have hotspot analysis run on.
-
For performance and prediction drift policies, only categorical features appear for hotspot selection.
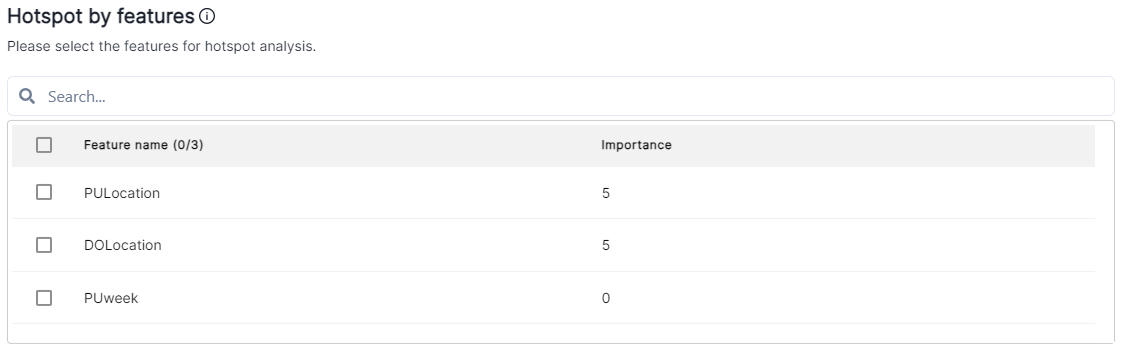
-
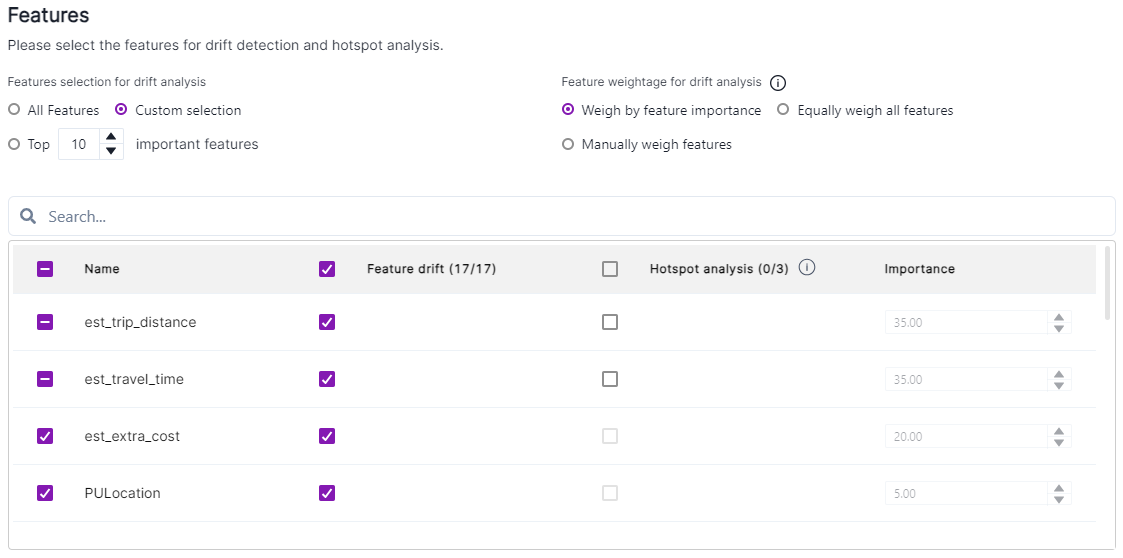
For feature drift policies, Features section shows all features in the list, and you can select a feature for feature drift, for hotspot analysis (although for hotspot analysis, only the categorical features have active checkboxes), or set the importance (if Manually weigh features is selected).
VIANOPS v2.1 release notes
New features in VIANOPS v2.1:
-
Root Cause Analysis (RCA)
- Hotspot analysis is now supported for feature drift, prediction drift and performance drift. A hotspot is a specific slice of data within a dataset where its drift shows a significantly higher value compared to other slices of data. Hotspot analysis is a technique that identifies hotspots.
- By default, all categorical features are used for hotspot analysis. You can also use subset of categorical features within a policy for hotspot analysis through APIs - Hotspot analysis.
- When a model triggers critical or warning alert, you can find a link on the alert called “hotspot”. This link opens a page with hotspot data and graphs to help you perform root cause analysis. You can find more details at UI - Hotspot analysis.
- This feature helps you identify anomalous behaviors in subsets of data even if the impact of those anomalies on the full dataset does not trigger an alert.
-
Model comparison
You can compare performance metrics of two models that are the same model type (classification or regression) and with the same input features and output. Model comparison is typically used to compare new version of model to current model in production or multiple deployments of same model in production. Additionally, you can compare models by segments.
- Project dashboard
- VIANOPS now opens to a project dashboard which provides a quick view on risk, volume, and recency for all models associated with the project.
- Use projects to group similar models addressing a business problem. Generally, projects are tied to some business problem like reducing customer churn or reducing customer escalation, and the models are developed to deliver the best results.
- UI - Projects
- Project management
- You can now create a new project or edit the name of an existing project. Projects are useful in grouping similar models.
- One-level project structure is currently supported.
- APIs - Projects
- UI - Create a project
- UI - Edit a project
- Performance policies
- Performance policies now have the same targets and baselines as the feature drift and prediction drift policies (daily, week-to-date, month-to-date, and quarter-to-date).
- UI - Performance policies
-
Feature importance
- You can now upload feature importance of the actual model via API for global explainability and then use feature importance as an additional weight method for overall feature drift.
- Global feature importance appears at the bottom of the model dashboard if it is a SHAP (SHapley Additive exPlanations) value.
- Global explainability helps you understand which features in a dataset have the strongest influence on a specific model’s output and which features are less important.
- APIs - Feature importance
- UI - Feature importance
- Custom binning for prediction (model output)
- User-defined bins for distance-based prediction drift policies on regression models
- The policy creation wizard flow includes bin entry for ease of creation. For example, define bins [10,15,25,50,100] results in four bins (10,15], (15, 25], (25, 50], (50-100], values fall outside left and right edge we still include them in the lowest and highest bins.
- APIs - Distance-based drift on prediction data
- UI - Prediction drift
- Segment management
- Create segments with complex conditions and rich operators including AND/OR, =, >, <, >=, <=, ≠
- Edit segment name and description
- APIs - Segments
- UI - Create Segments
- Data profile monitoring as part of feature drift policy
- Data profiling covers metrics of Count, Min/Mean/Max, Quantiles (25%/50%/75%, 1%/99%, 5%/95%, 10%/90%), and Mean Std
- APIs - Data profiling
- UI - Data profiling
Improvements and enhancements in VIANOPS 2.1:
- Policy management
- Visualize additional information including alert count, policy type, and next run
- Toggle between active and inactive policies
- Policy management with Duplicate operation
- In addition to create and edit, a new action is added for each policy in the Policy List to duplicate the policy. This is useful in creating a similar policy without having to start from scratch.
- UI - Create a policy
-
Scale: support unlimited number of features of a model
- Quick validation of a new segment during creation
- When creating a segment, if you have loaded data with inference mapping, the Segments wizard shows how many rows of data are associated with the segment according to the conditions you have specified.
- Segments
- Added performance metric for regression model policies in the UI
- Added R-squared (R2) metric to the performance drift policies for regression models.
- Metrics
-
Added performance metrics for binary classification model policies in the UI
The following metrics are now available for binary classification models:
- Area under the curve (AUC) — The area under the ROC curve, which quantifies the overall performance of a binary classifier compared to a random classifier.
- Gini coefficient — A measure of inequality or impurity in a set of values, often used in decision trees.
- Lift — A measure of the effectiveness of a predictive model calculated as the ratio between the results obtained with and without the predictive model.
- Log loss — A performance metric for classification where the model prediction is a probability value between 0 and 1. Measures divergence of model output probability from actual value. Logloss = 0 is a perfect classifier.
- Probability calibration curve — A plot that compares the predicted probabilities of a model to the actual outcome frequencies, used to understand if a model’s probabilities can be taken at face value.
See metrics.
- Search in tables now works throughout the UI.
VIANOPS v2.0 release notes
2.0 is the release with special focus on ML model monitoring. With the new name of VIANOPS, the platform now uniquely brings together observability across layered, high-volume, complex dimensions, with root cause analysis for high-risk hotspots that jeopardize model behavior, and the ability to drive high-performance ML operations across any cloud and any data source.
New features in VIANOPS 2.0:
-
A free trial version of VIANOPS is available starting with this release. It includes a sample model that shows key parts of the platform flow.
- Sign up: https://vianops.ai
- Tour: VIANOPS free trial tour
-
New user experience with dashboards.
- New, more dynamic user interface.
- A model dashboard with model performance and prediction metric graphs, alerts summary and recent alerts list, and easy access to policies and segments.
-
Performance monitoring policy.
- Use performance policies to monitor day-over-day performance changes and trigger alerts when performance drops significantly.
- Performance
- Deferred Ground truth ingestion.
- Drift metric selection for feature drift or prediction drift monitoring.
- You can choose either Population Stability Index (PSI) or Jensen-Shannon (JS) divergence as the metric for feature or prediction drift.
-
Segments as model level objects and monitoring policies for the segments.
- You can define any slice of data as a segment and monitor the feature drift, prediction drift, or performance of this segment in the corresponding policy.
- You can select multiple segments in a single policy to easily compare the drift or performance across segments.
- Segmentation enables monitoring for specific use cases as well as more granular root cause analysis when a model is not performing as expected.
- Segments
-
Custom bins for prediction or any feature.
- You can set custom bins for distance-based drift policies for either prediction or feature drift.
- Prediction drift (see the baseline_bins table item)
- Feature drift (see the baseline_bins table item)